
How does hearing loss affect our ability to pay attention to speech?
The acoustic properties of speech vary in many ways, such as in basic characteristics of frequency (pitch) and amplitude (loudness), and in more complex ways such as spectrotemporal modulations, speech rate, and timing. When a listener has damage to their ears due to aging and noise exposure, the ability to detect and encode these features in the ear diminishes. If these sound cues are not available, they cannot be used to help a listener select the speech that they are interested in when listening in the presence of other talkers or environments with background noise.
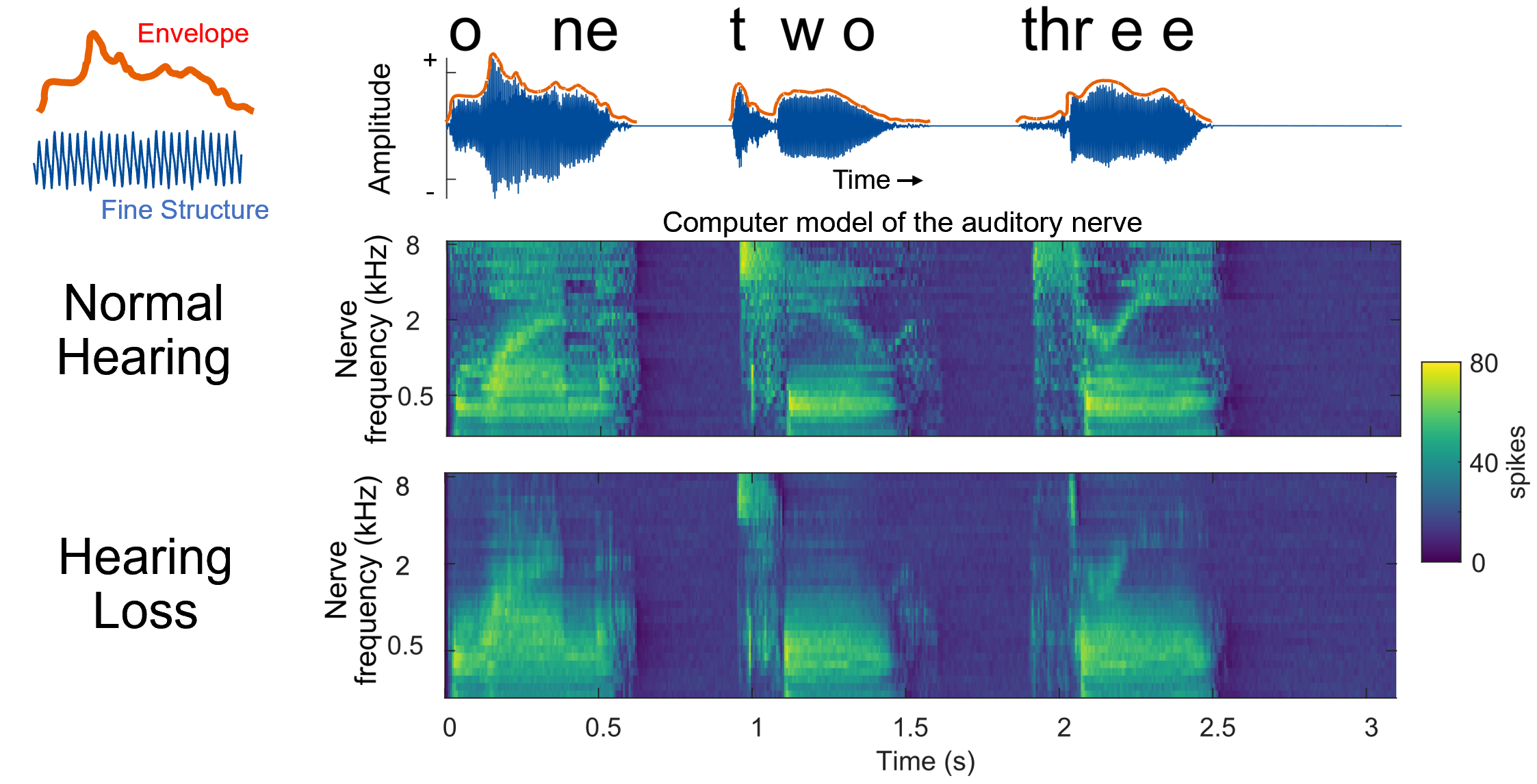
Not all hearing loss is the same. Structures of the cochlea, the primary hearing organ, can be damaged in many configurations. Although it is hard to tease apart what is damaged, clinical tests and physiological measures can help us understand exactly how a person’s hearing is affected. Our goal is to draw a better line between problems of attention and speech understanding to the status of a person’s hearing.
One of the main questions we ask is, can we map how patterns of damage to the ear affect how a person forms auditory objects and is able to perform sensory selection?
Example Publication:
Paul, B. T., Uzelac, M., Chan, E., & Dimitrijevic, A. (2020). Poor early cortical differentiation of speech predicts perceptual difficulties of severely hearing-impaired listeners in multi-talker environments. Scientific Reports, 10:6141. doi:10.1038/s41598-020-63103-7
